
Nous sommes sur le point de comprendre presque tout sur la dynamique basée sur la position (PBD). En lisant ces deux articles sur PBD et son successeur XPBD, j’ai vite réalisé qu’il y avait de nombreux concepts qui m’étaient totalement inconnus. Alors, j’ai encore une fois décidé d’écrire à leur sujet.
J’écrirai cette semaine sur la boucle de simulation de PBD, ligne par ligne, afin de mieux la comprendre tout cela. Dans le prochain article, j’écrirai sur le successeur de PBD, XPBD. À la fin, je choisirai entre PBD et XPBD comme boucle de simulation pour passer à la mise en place d’une simulation de tissu.
L’algorithme de la dynamique basée sur la position (PBD)
Voici l’algorithme pour exécuter une simulation avec PBD :

Figure 1 : L’algorithme de simulation de PBD - J. Bender, M. Müller and M. Macklin / A Survey on Position Based Dynamics, 2017
Les lignes (1)-(3) servent à initialiser la position et la vitesse des particules, car le système est du second ordre par rapport au temps : . Sinon, il y aurait trop de variables inconnues.
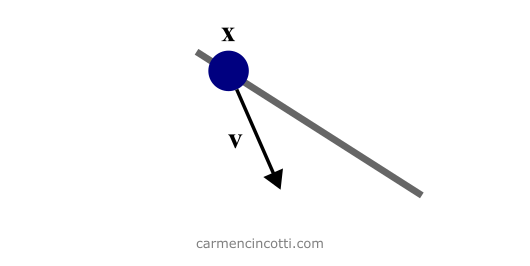
Figure 2 : Initialisation de PBD. La particule x est contrainte à la ligne (en gris). Il a une vitesse de vecteur v.
Rappelons que PBD travaille exclusivement et directement sur les positions des particules dans un système. Il n’est donc pas nécessaire de maintenir la couche d’accélération pour calculer la vitesse et donc la position dans les étapes futures.
La boucle
On entre maintenant dans la boucle de simulation ! À chaque itération, on prend un pas dans le temps, pour faire avancer la simulation.
Les lignes (5)-(6) (de Figure 1) effectuent une étape d’intégration d’Euler symplectique pour faire avancer la position et la vitesse. Le nouvel emplacement, est juste une prédiction de la position finale de la particule non soumise à aucune contrainte. Nous ne considérons les contraintes que plus tard.
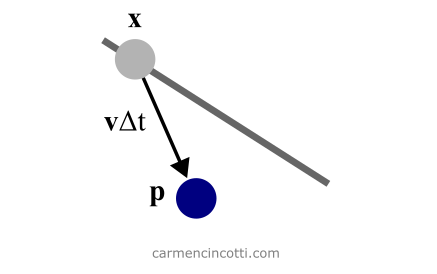
Figure 3 : La prédiction de la position x de la particule. La prédiction est représentée par une deuxième variable temporaire p.
L’intégration d’Euler symplectique
L’intégration typique d’Euler fait avancer un système dans le temps , ou appelé ici, comme suit :
Notez bien que la vitesse est mise à jour après la mise à jour de la position . Cependant, cette méthode augmente l’énergie potentielle du système qu’elle simule. Pour lutter contre cela, on utilise l’intégration d’Euler symplectique :
Nous déterminons d’abord la vitesse du système dans le pas de temps désigné, , puis utilisons cette nouvelle vitesse pour calculer la position.
Voici cette vidéo pour en savoir plus :
À la ligne (7), on continue avec la génération des contraintes externes non permanentes telles que les contraintes de collision. Nous devons les générer à ce moment précis pour effectuer la détection de collision continue avec la nouvelle position prédite, , de l’étape précédente. Je reviendrai sur le sujet des collisions dans un article ultérieur.
Le solveur de Gauss—Seidel “non linéaire”
Pendant les lignes (8)-(10), un solveur corrige itérativement les positions prédites, afin de satisfaire les contraintes définies dans le système.
Dans l’article A Survey on Position Based Dynamics, 2017 - Jan Bender , Matthias Müller et Miles Macklin, il y a cette idée d’un solveur Gauss—Seidel non-linéaire, car Gauss-Seidel est généralement utilisé pour résoudre des systèmes linéaires. Rappelons que la différence entre les contraintes linéaires et non linéaires est la suivante :
- Linéaire - Les contraintes d’inégalité linéaires ont la forme . Les contraintes d’égalité linéaires ont la forme .
- Non linéaire - Les contraintes d’inégalité non linéaires ont la forme . De même, les contraintes d’égalité non linéaires ont également la forme .
La méthode de Gauss—Seidel
On utilise la méthode de Gauss—Seidel pour résoudre un système d’équations linéaires. Rappelons qu’une équation linéaire prend la forme :
Notez bien que cette méthode numérique est itérative. Autrement dit, on utilise une boucle pour approcher itérativement une solution approximée… ce qui m’a fait réfléchir. Pourquoi dois-je utiliser une méthode numérique pour résoudre une équation comme ? Voici une excellente ressource (diapositive 2) qui répond à cette question.
En regardant cet exemple de la méthode en action - on voit ce qui est particulièrement intéressant sur cette méthode. Nous remplaçons les anciennes valeurs par nos toutes nouvelles valeurs calculées numériquement à chaque itération.
En appliquant ces connaissances concernant la satisfaction des contraintes dans le système, on voit que chaque équation contrainte sera résolue individuellement et le résultat de l’une sera immédiatement impliqué dans le calcul de l’autre. Cependant, notre système n’a qu’une seule contrainte pour être plus simple comme exemple. Imaginons que s’il y en avait deux que lors d’une itération, le résultat de l’un influencerait immédiatement le résultat des autres.
Dans tous les cas, le but est de résoudre les contraintes comme dans cette image ci-dessous :
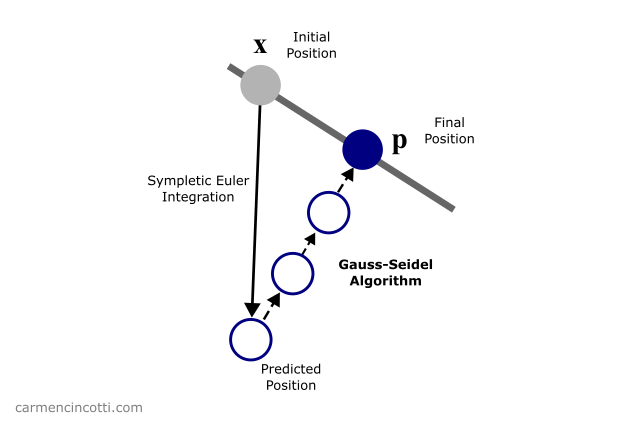
Figure 4 : L’algorithme de Gauss—Seidel en action. La position prédite p est déplacée pour satisfaire la contrainte (la ligne grise).
Plus précisément, nous souhaitons mettre itérativement à jour pour satisfaire nos contraintes :
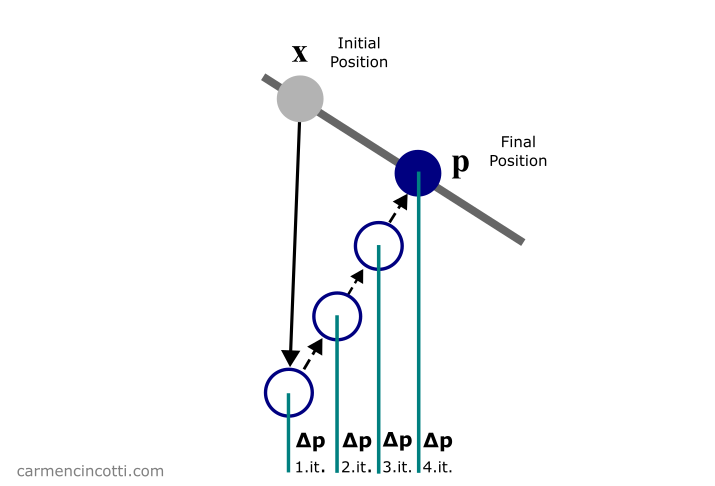
Figure 5: La position prédite p est déplacé itérativement de pour satisfaire la contrainte (la ligne grise).
Génial ! Nous avons un solveur prêt à nous aider à résoudre le système 🎉 ! Cependant, nous avons une petite question à laquelle nous devons répondre 🤔 :
Comment trouver ?
Corriger la position des particules avec la méthode de Newton Raphson
Pour trouver le déplacement de la particule , nous utiliserons un processus basé sur la méthode de Newton-Raphson.
La méthode de Newton—Raphson
Le but de la méthode de Newton—Raphson est de déterminer itérativement les racines d’une fonction arbitraire et non linéaire. Autrement dit, on minimise cette fonction (supposons une fonction ) en trouvant la valeur de qui fera .
Prenons par exemple cette fonction . On commence par supposer que la valeur minimisera la fonction. On trace une droite tangente à la courbe comme ceci :
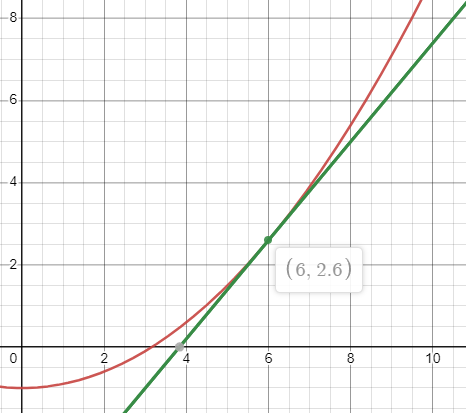
C’est clair que n’est pas minimisé par , car . Nous continuons à chercher des racines en réessayant à :
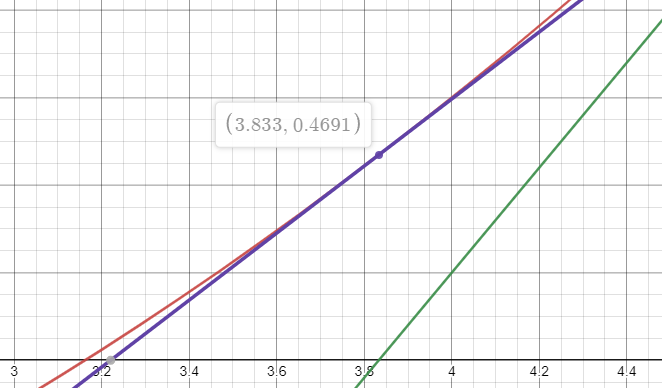
Enfin, on répète ce processus pour enfin trouver la racine .
En suivant la méthode de Newton-Raphson, nous voulons linéariser les fonctions de contrainte. Dans le cas d’une contrainte d’égalité, elle est approximée en la linéarisant comme suit :
Pour maintenir le moment linéaire et angulaire, on restreint dans la direction de :
où est les masses des particules (on les inverse pour pondérer les corrections proportionnelles aux masses inverses). À première vue, je me suis dit : euh, quoi ? Cependant, j’ai créé quelques graphiques pour au moins clarifier cette équation (même si je suis encore perdu sur la conservation des moments).
Imaginons qu’il y a une fonction contrainte . L’idée est que nous voulons qu’un point arbitraire reste sur cette ligne indépendamment des forces externes :
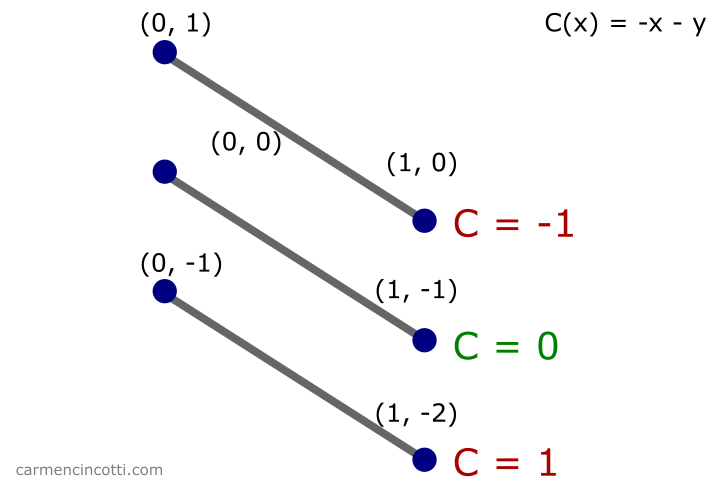
Nous voulons minimiser . Pour ce faire, on voyage dans le sens du gradient de , :
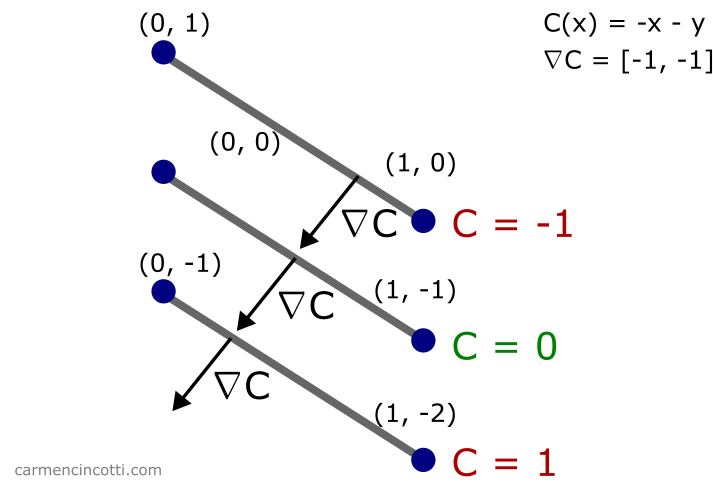
Si je place arbitrairement un point sur ce graphique et ensuite j’aimerais que le point reste toujours sur - il est logique que je le fasse voyager dans la direction du gradient de pour revenir le plus vite possible à la ligne !
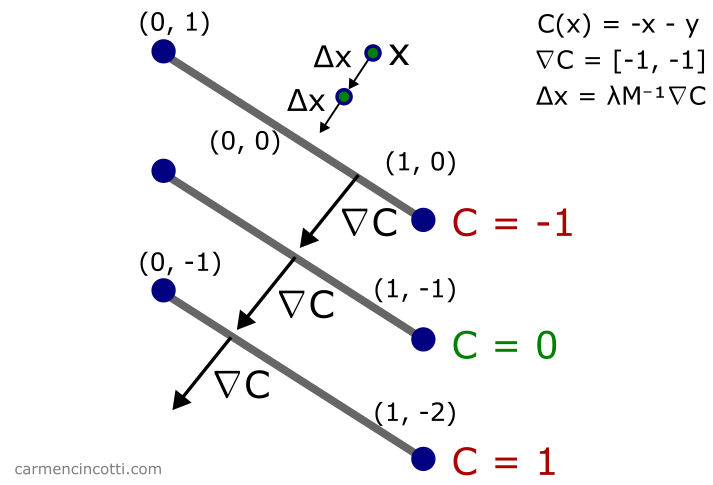
Notre prochaine étape consiste à trouver la valeur de notre multiplicateur de Lagrange (un facteur scalaire) et puis à calculer . La réécriture de l’approximation linéaire de est la suivante :
où
On peut effectuer une substitution pour trouver :
Après avoir enfin trouvé et par conséquent , on met à jour .
Rappelons que est une variable de position temporaire. On met à jour notre variable de position originale dans l’étape suivante.
Ensuite, nous passons par une autre itération du solveur “non linéaire” de Gauss-Seidel.
La mise à jour finale avec l’intégration de Verlet
Pendant les lignes (10)-(12) - après le solveur de Gauss-Seidel, on met à jour la position et la vitesse de chaque particule à l’aide d’une méthode d’intégration qui s’appelle intégration de Verlet :
Avec l’intégration de Verlet - au lieu de stocker la position et la vitesse de chaque particule, nous stockons sa nouvelle position et sa position précédente . Comme vous pouvez le voir, avec eux, nous pouvons calculer la nouvelle vitesse, !
Ensuite, la boucle recommence et nous recommençons tout le processus ! 🎉
Prochainement…
PBD peut être étendu pour fournir des simulations plus agréables visuellement par son successeur XPBD. Nous verrons cela dans le prochain article !
Des ressources (en français et anglais)
- Non-linear Gauss-Seidel solver - Real-Time Physics Simulation Forum
- Advanced Character Physics - Thomas Jakobsen
- Efficient Simulation of Inextensible Cloth - Rony Goldenthal, David Harmon, Raanan Fattal, Michel Bercovier, Eitan Grinspun
- A Survey on Position Based Dynamics, 2017 - Jan Bender , Matthias Müller and Miles Macklin
- Position-based simulation of elastic models on the gpu with energy aware gauss-seidel algorithm - Ozan Cetinaslan
- Simulation of Mooring Lines Based on Position-Based Dynamics Method - Xiaobin Jiang, Hongxiang Ren, Xin He
- Iterative methods for Ax = b - www.robots.ox.ac.uk