
When studying multivariable calculus, we often come across the use of matrices to represent different concepts. We often come across the Jacobian, the Hessian and the gradient.

These concepts are close to each other, by virtue of being matrices having to do with derivatives of functions, However, each matrix has its own derivation, and signification.
What is the difference between the Jacobian, the Hessian and the gradient 🤔? We will discover it together in this article. During this mathematical journey, we will also study the concepts of the difference between vector-valued functions and scalar-valued functions.
The Gradient
We start with the gradient which we already talked about a few weeks ago. The gradient is a vector composed of the partial derivatives of a scalar-valued function, :
where is called nabla. It is sometimes called “del”. It denotes the vector differential operator.
Recall that the gradient measures the direction and the fastest rate of increase of a function at a given point.
Let’s imagine that we are at the foot of a mountain, and we wanted to climb it as quickly as possible. We see that the right track is to climb it in the direction of the arrow:
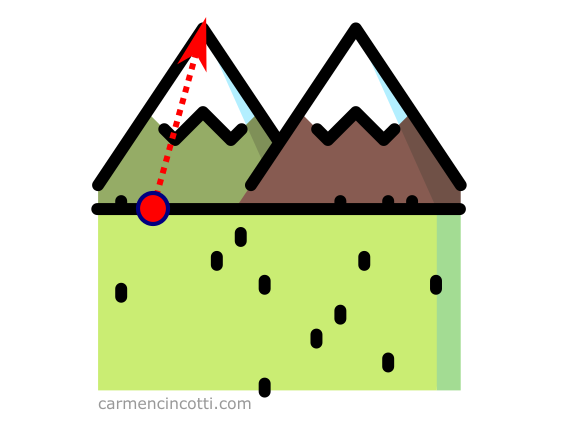
This arrow represents the gradient because it is the fastest ascent up the mountain.
A scalar-valued function
A scalar-valued function is a function (multi-variable / of dimension ) that returns a scalar value:
For example, if we evaluate at the point (2,1), we get the scalar, 3:
How to calculate the Gradient
Let’s take an example. I have a function defined as . First, we need to find the partial derivatives with respect to the variables and as follows:
This gives us a gradient:
The Hessian
If we follow the explanation of the gradient, the Hessian will also be easy to understand. It is the derivative of the gradient of a scalar-valued function . For instance :
Using again the function , we will see a Hessian matrix as follows:
Some applications of the Hessian matrix are the following:
-
Quadratic approximations of a multivariable function. This is a closer approximation to the function than the local linear approximation we already discussed several weeks ago.
-
The partial second derivative test - it is used to find saddle points, the maxima and the minima of a function.
The Hessian determinant
The Hessian determinant plays a role in finding the local maxima/minima of a multivariable function. We will see what a determinant is in a later article. For now, I’ll just explain how to calculate it. I present to you once again the Hessian matrix that we have already calculated in the last part:
In order to find the determinant, we need to follow the framework below:
Therefore,
The Jacobian
The Jacobian is a matrix that holds all first-order partial derivatives of a vector-valued function:
The Jacobian form of a vector-valued function is therefore the following:
For example - if we have a vector-valued function like:
The Jacobian matrix will be :
By using the Jacobian, we can locally linearize a vector valued function at a specific point.
Linear functions are simple enough that we can understand them well (using linear algebra), and often understanding the local linear approximation of f $$ itself.
To learn more about the calculation, here is a video that helped me a lot:
The determinant of the Jacobian matrix
We can use Jacobian matrix of a vector valued transformation to find its determinant. To do this with a transformation of , we use the framework:
Consider this example using this Jacobian matrix:
We can calculate the determinant as follows:
What does the determinant mean? 🤔 The function gives us the amplitude in which space contracts or expands during a transformation around a point .
For example, if we evaluate it at the point , we will see:
Which tells us that the space does not change around this point! However, around the point , we see another story:
I recommend this resource in order to visualize the transformations and the determinant for each one!
Resources
- Ask Ethan: What is A Scalar Field? - Forbes
- A Gentle Introduction To Hessian Matrices - Machine Learning Mastery
- A Gentle Introduction to the Jacobian - Machine Learning Mastery
- Vector and scalar functions and fields. Derivatives
- What is the Jacobian matrix? - Stack Exchange
- The Hessian - KhanAcademy
- What is the difference between the Jacobian, Hessian and the Gradient? - Stack Exchange