
AWS (Amazon Web Services) is a cloud platform and cloud tooling suite provided by Amazon.
The list of AWS’s offerings ranges from Compute Servers (EC2), Storage (S3), Databases (RDS, DynamoDB), Networking & Content Delivery, Analytics, Machine Learning, etc.
You can view all of AWS’s product offerings here on their Explore Products page.
With that said, AWS is expensive.
Over the next few articles, we’ll take a look at some very easy solutions (sometimes just by clicking a button) that you can take advantage of in AWS to save some serious cash!
Contribute
Have an idea for easily reducing AWS fees? Please leave a comment at the bottom of the page!
How To View Your AWS Monthly Bill
We can access our monthly AWS bill by going to the AWS Billing Console.
Then, from the left-hand menu, we can select Bills.
At the top of the page, you’ll see the AWS estimated bill summary which outlines your current month of expenditures.
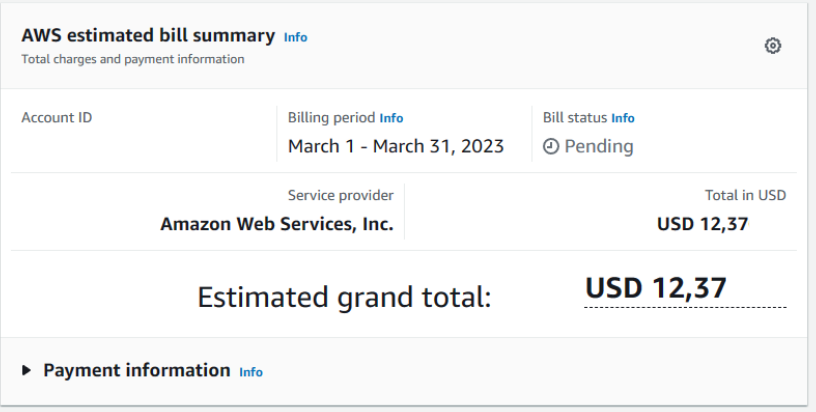
Upon scrolling down, you’ll be able to view an itemized bill of your expenses.
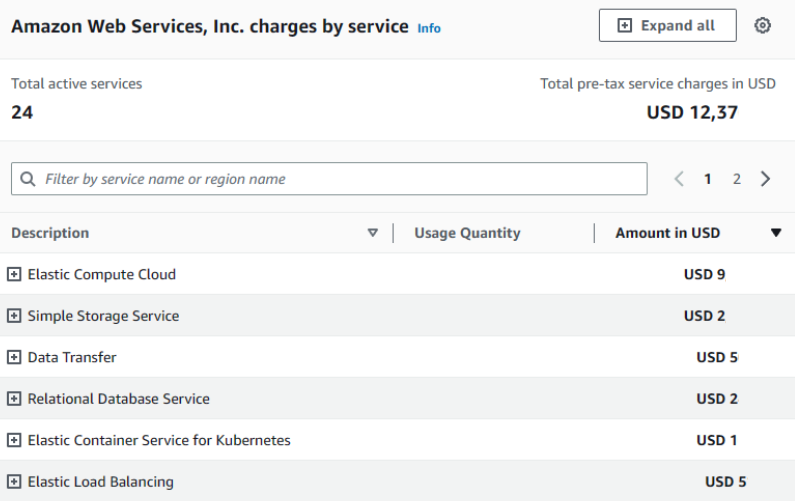
Pre-Req: Delete Unused Resources
This goes without saying, if a resource is no longer being used, you should delete it.
Why? — AWS, in most cases, has quite a bit of no-so-obvious hidden costs.
Example of a Hidden Cost — EBS Volumes Attached to EC2 Instances
For this example, let’s assume I wanted to launch an EC2 instance in order to prototype a new feature.
Upon launching the instance, I attach a 2 TB EBS volume.
After prototyping, I then stop the instance since my prototyping phase is now complete.
Fast forward 1 month later… I check my bill and lo-and-behold… I’m still paying $200 a month.… What? How?
I never deleted the 2 TB EBS Volume that I attached to the EC2 Instance! I’m being charged for that unused storage!.
It’s important to double-check your outstanding resources to confirm that AWS isn’t charging you for hidden items that you may have forgotten about.
AWS S3 (Simple Storage Service)
You probably already know all about S3 if you’ve found this article… but I’ll provide some information if you have never heard about it.
Amazon S3 (Simple Storage Service) is a highly scalable and secure object storage service offered by Amazon Web Services (AWS).
S3 stores data as objects, which consist of a file and metadata.
Additional S3 features include High durability and availability, Security, Scalability, Integration with other AWS services such as EC2, Lambda, and CloudFront to create powerful applications and workflows.
However… storing carelessly a lot of data can be expensive!
The (Expensive) Costs of S3
Data costs in S3 depend heavily on the storage class tier selected. Let’s look at a couple Storage Classes, their specs, and prices:
| S3 Standard | S3 Intelligent-Tiering* |
S3 Standard-IA |
S3 Glacier IR |
|
|---|---|---|---|---|
| Durability |
(11 9’s) | (11 9’s) | (11 9’s) | (11 9’s) |
| AZs | ≥3 | ≥3 | ≥3 | ≥3 |
| Retrieval charge | N/A |
N/A |
per GB retrieved |
per GB retrieved |
| Latency | ms | ms | ms | ms |
| Cost | 0.023 / Gb | Varies | $0.0125 / Gb | $0.004 / Gb |
S3 offers quite a bit of different storage classes. The variable that differentiates these classes is the retrieval time to access the data and the additional costs that one may incur by accessing colder storage options..
Let’s take a look at this in the next section.
Selecting Cheaper Storage Classes
Assuming that you upload data to S3, you should be selecting the cheapest storage class to fit your needs.
Let’s take a look at a few different storage classes together. You can see the list in full form here.
Choosing S3 Standard
S3 Standard is considered the hot tier for data access. Therefore, you pay the highest per Gigabyte of storage in exchange for the fastest retrieval speed at no extra costs.
When to use this storage class: The S3 data is accessed frequently (daily, weekly, and potentially monthly).
Choosing S3 Standard Infrequent Access (IA)
S3 Standard-IA is considered a lukewarm tier for data access when compared to S3 Standard. Costs of data storage can 40% cheaper than S3 Standard. Although, there is a per-GB charge for accessing data..
When to use this storage class: The S3 data is accessed rather infrequently (possibly bi-weekly, monthly).
Personally, 40% is such a large cost cut that I believe most data that isn’t accessed regularly should definitely live in this tier.
Choosing Amazon S3 Glacier Instant Retrieval (IR)
Out of the instant access tiers, Amazon S3 Glacier Instant Retrieval is the coldest tier. However, the cost benefits of this tier are huge — 68% less in data storage costs when compared to S3 Standard.
When to use this storage class: The S3 data is accessed rarely (every few months, yearly).
Can’t Decide What S3 Storage Class To Choose?
If you’re like me — choosing a storage class seems like such a chore. How can we get these super deep cost savings and not have to study and understand our data access patterns all in the name of saving money?
Well… there is a way to avoid all this guess work by choosing a fairly unknown, but extremely important storage class when it comes to saving money. We will see it in the next part.
How do you choose storage classes? Leave a comment below.
The “Hands Off” AWS S3 Money Saving Class — S3 Intelligent-Tiering
In my opinion, the quickest way to save money with S3 is to use Intelligent Tiering. This is a storage class that you can enable in just 5 minutes!
What is AWS’s Intelligent Tiering Storage Class?
AWS’s Intelligent Tiering Storage Class is AWS’s solution for automatic classification of data in order to maximize cost savings all while removing the need for the user to manage and move data across storage class’s themselves.
By default, data stored in Intelligent Tiering is moved across three tiers:
- Within first 30 days: Frequent Access Tier (think S3 Standard) — 0% Savings
- Days 30-90: Infrequent Access Tier (think S3 Standard-IA) — 40% Savings
- Days 90+: Archive Instant Access Tier (think S3 Glacier Instant Retrieval) — 68% Savings
Additionally, and unlike having your data solely in S3 Standard-IA or S3 Glacier Instant Retrieval… there is no data retrieval charges!.
What’s the catch? You’re charged a very very small premium for the monitoring and automatic movement between classes of data as data access patterns change.
The 5 Minute Hack: The One Day S3 Lifecycle Method
Now that we have a better understanding of what Intelligent Tiering is and *how we can save up to 68% of S3 Costs, let’s see how we can enable it!
A very fast and easy way to move all of your data into Intelligent Tiering immediately is to use S3’s Lifecycle Methods.
Step 1: Access the S3 Bucket Lifecycle Menu
First, login to AWS’s UI and navigate to the S3 Console, then choose the S3 bucket that you would like to convert to Intelligent Tiering. In my example, I have a bucket named s3bucket:
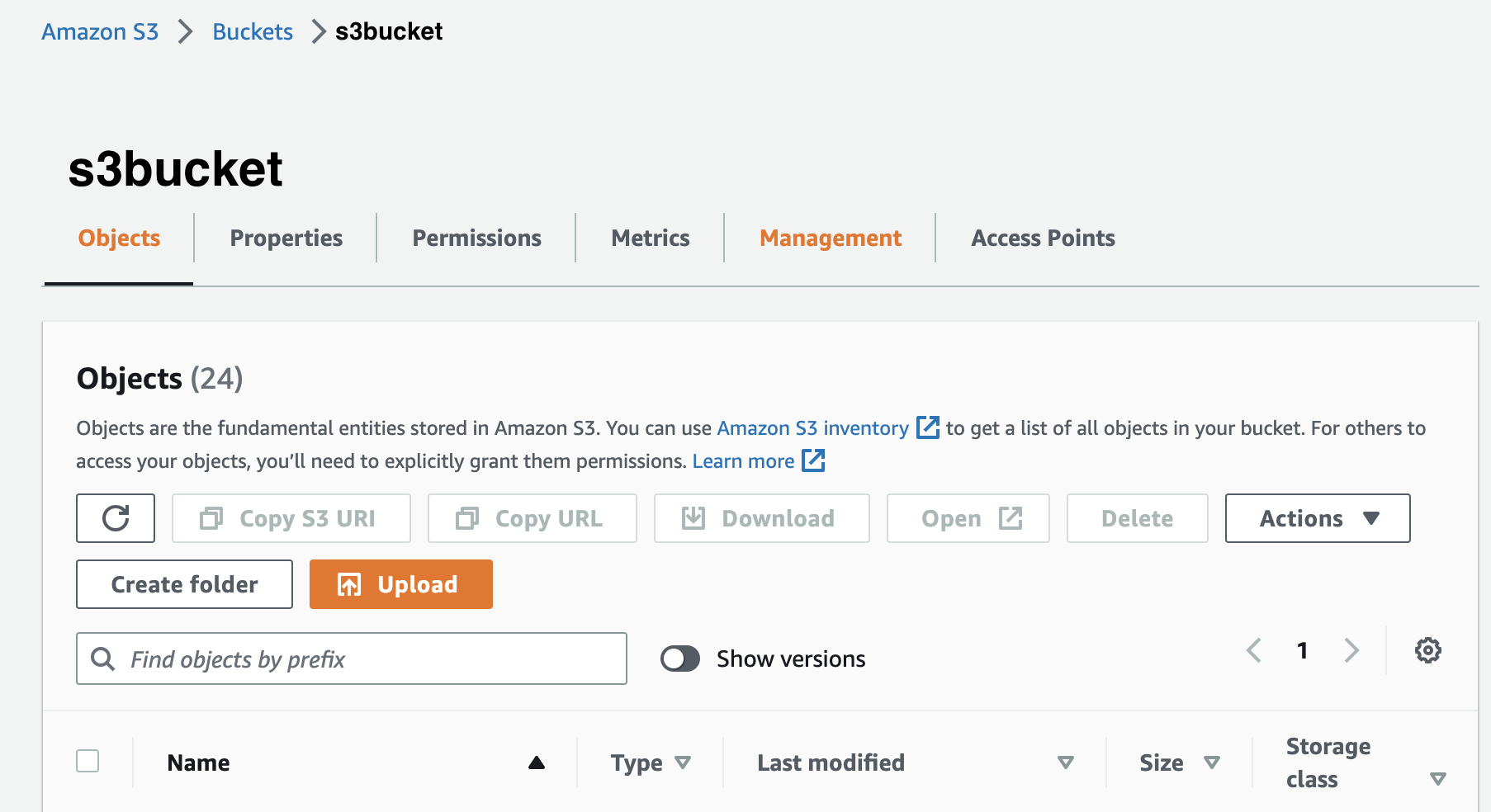
Next, in the S3 Bucket horizontal menu at the top of the page, choose Management.
You’ll see a panel now available titled Lifecycle Rules. Click Create lifecycle rule.
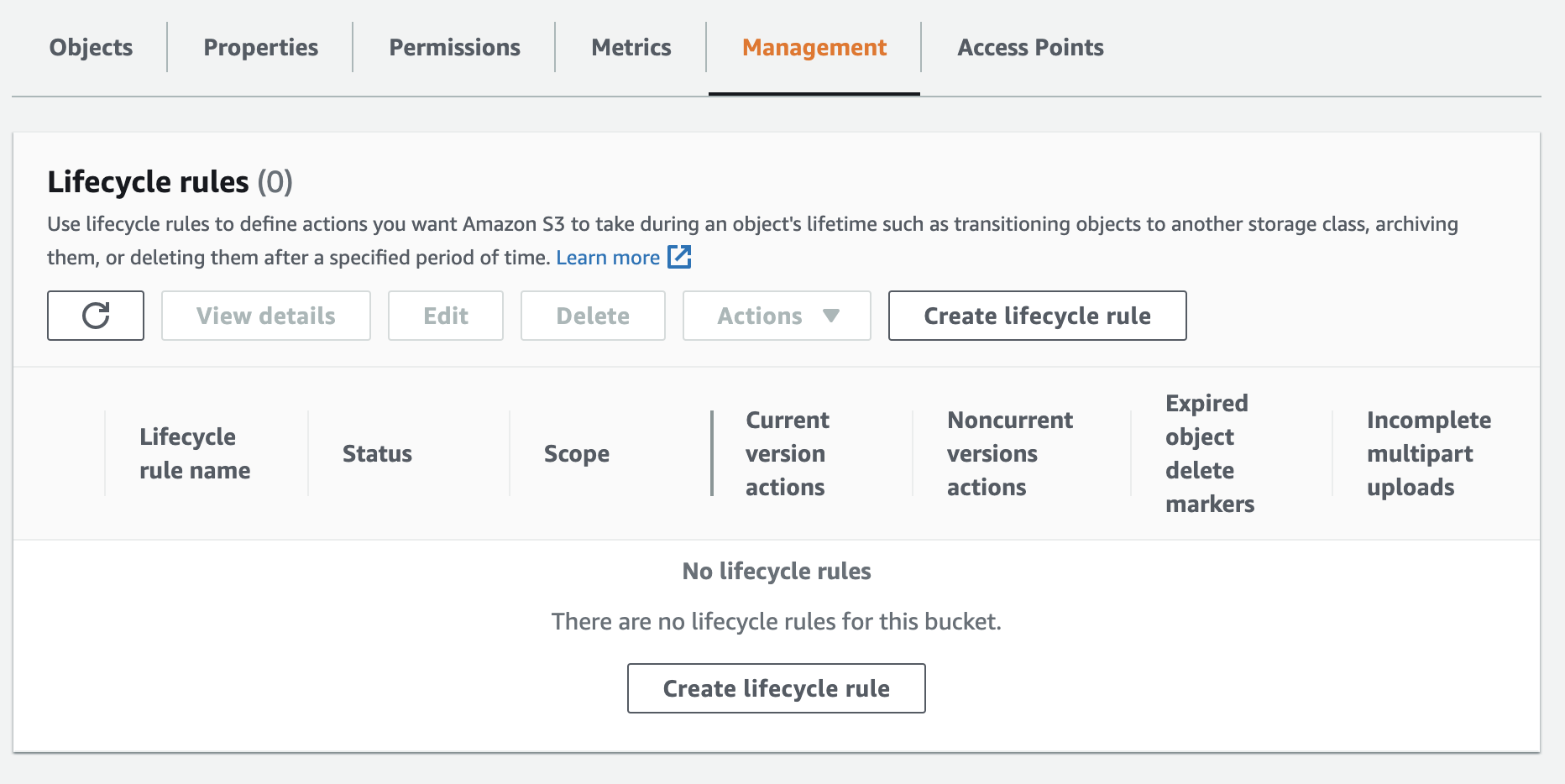
Now we’ll work on configuring the lifecycle rule!
Step 2: Creating the S3 Lifecycle Rule
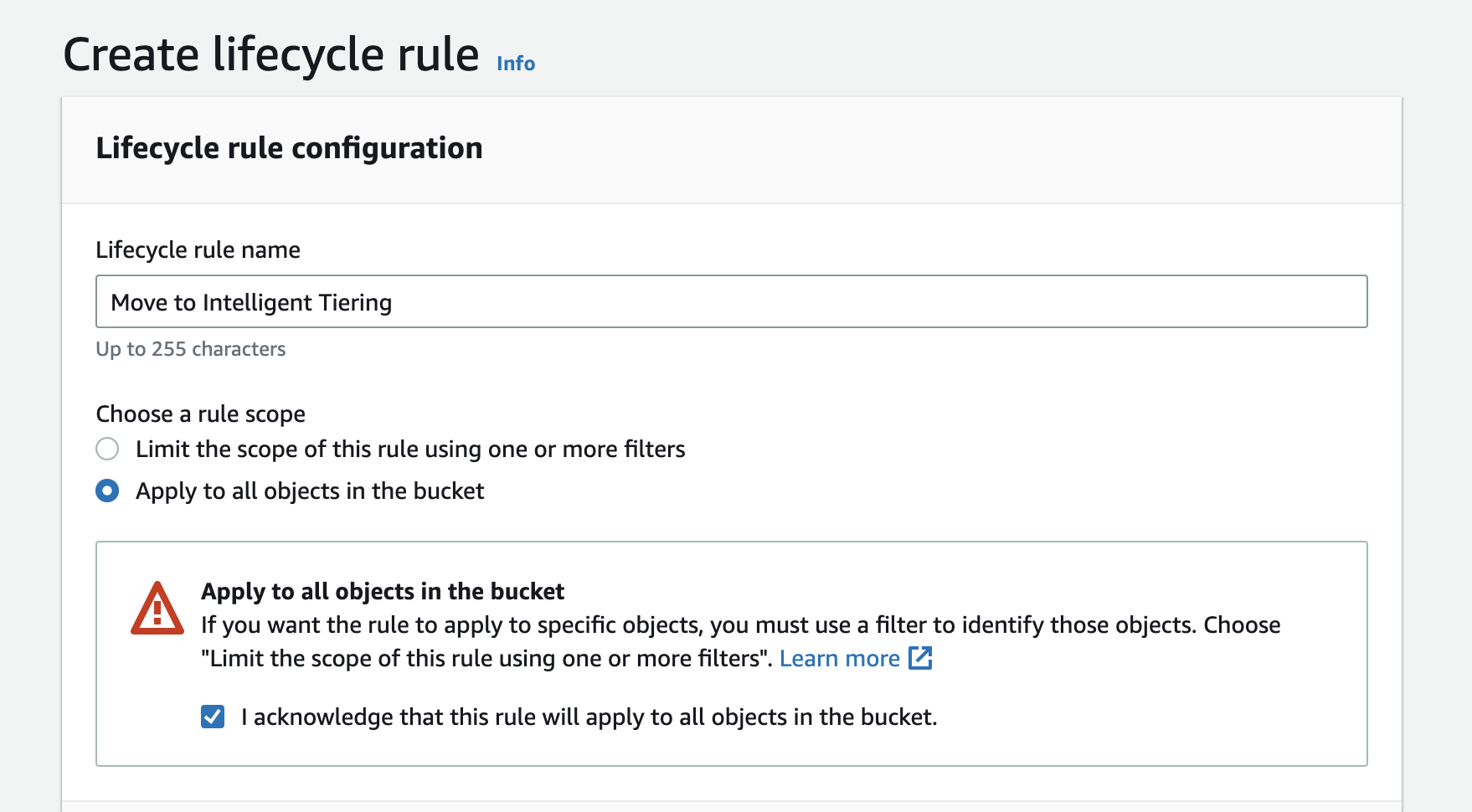
- Enter a Lifecycle rule name, it can be whatever you please. I am choosing “Move to Intelligent Tiering”:
-
Click Apply to all objects in the bucket. A warning will come up immediately after. If you agree with the terms of the warning, click “I acknowledge that this rule will apply to all objects in the bucket.”
-
Under “Lifecycle rule actions”, check the box “Move current versions of objects between storage classes”:
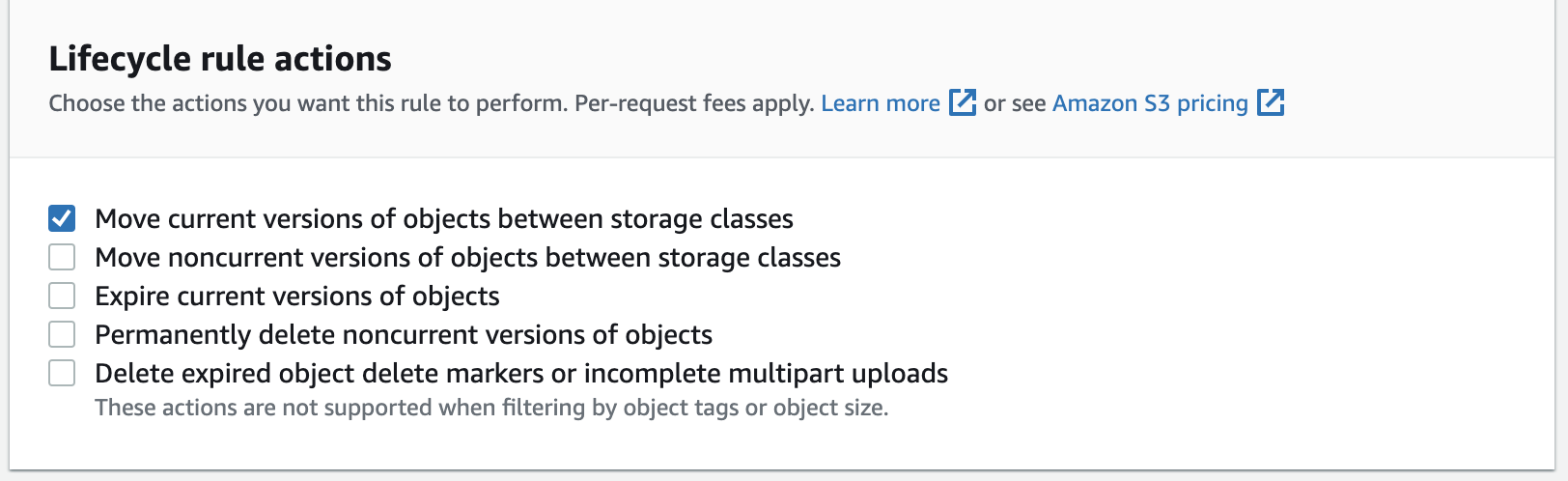
- A new menu will appear that is titled “Transition current versions of objects between storage classes”. Select Intelligent-Tiering from the dropdown menu titled “Choose storage class transitions”. For “Days after object creation”, choose 1.
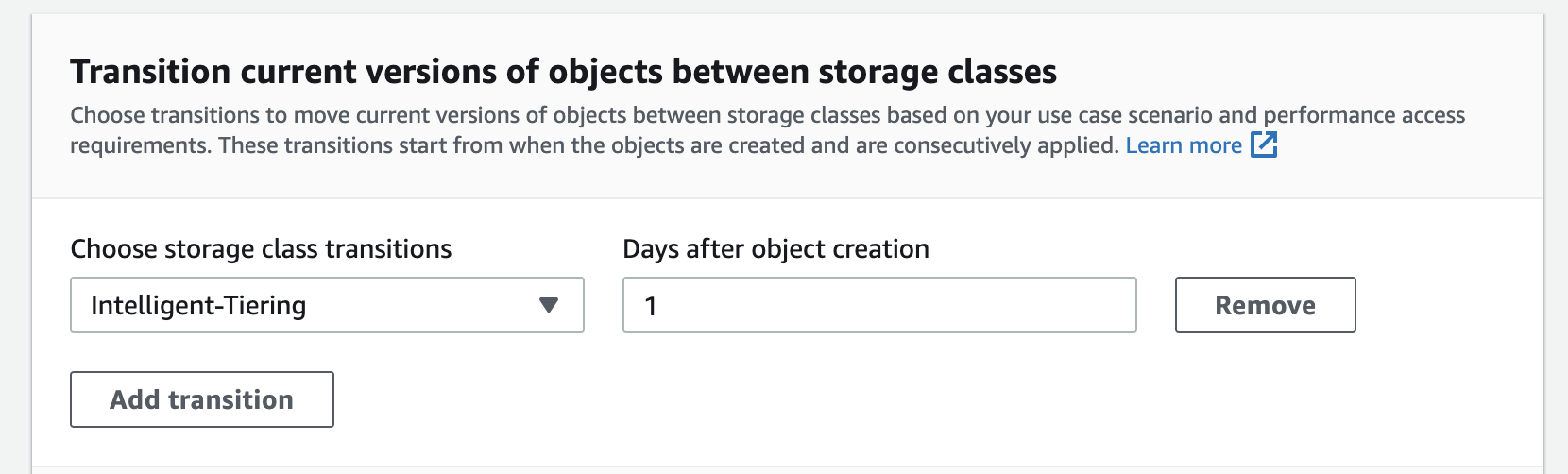
- Confirm the configuration, then press Create rule.
AWS will now work on transitioning all the S3 data to Intelligent Tiering that has been within the S3 bucket for atleast 1 day.
Intelligent Tiering FAQ
When does the Intelligent Tiering internal transition timer start?
Intelligent Tiering’s transition timer starts immediately after being moved to Intelligent Tiering and is not tied to the creation timestamp of the object in S3.
Here’s a quick example:
- Day 0: I create an S3-Standard object in S3
- Day 15: I reclassify this object’s storage class to Intelligent-Tiering
- Day 45: After 30 days of not accessing the object, Intelligent Tiering moves the object to the infrequent-access (and cheaper) tier.
As you can see, the Intelligent Tiering timer waited 30 days after the object’s storage class was reclassified to Intelligent Tiering.